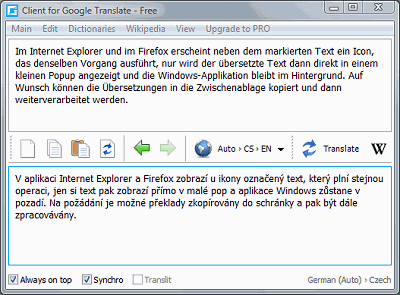
von
von Entwickler von Google veröffentlichten ein neues Verfahren, wie ein Übersetzungswörterbuch zwischen zwei beliebigen Sprachen erstellt, erweitert und optimiert werden kann:
Der Computer lernt an einer riesengroßen Menge von einsprachigen Texten jeder der beiden Sprachen ihre sprachliche Struktur: bei jedem einzelnen Wort wird nicht nur seine Häufigkeitsfrequenz analysiert, sondern z. B. auch die Wörter, die davor und danach stehen – so kann statistisch die Wahrscheinlichkeit einer bestimmten Wortfolge festgelegt werden.
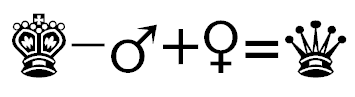
Symbolisch ausgedrücktes Beispiel einer analogen Relation in verschiedenen Sprachen
Aufgrund der Strukturanalyse wird die ganze Sprache als ein System von untereinander verknüpften Wörtern definiert, das ein mathematisches Modell bildet.
Da sich gegenwärtige Sprachen strukturell ähnlich sind – sie widerspiegeln nämlich die Struktur derselben Welt –, kann dieses mathematische Modell – der Wortschatz einer Sprache – beim Vergleich von bekannten zweisprachigen Übersetzungen analog in die zweite Sprache projiziert werden, woraus die Übersetzung der Ausdrücke abgeleitet werden kann, die im Übersetzungswörterbuch bislang nicht enthalten sind.
Die neue Technologie wird in die Systeme der Maschinenübersetzung wie Google Translate implementiert und soll zu ihrer weiteren Verbesserung beitragen.
Tomas Mikolov, Quoc V. Le, Ilya Sutskeve: Exploiting Similarities among Languages for Machine Translation
Bild: Radim Sochorek