

 von
von Am Beispiel der französischen Open Source-Software TextStat wollen wir uns zeigen, was eine Konkordanzsoftware ist und wozu sie dienen kann.
Jeder Text besteht aus Buchstaben, Wörtern, Sätzen, Absätzen usw. TextStat kann Text- und HTML-Dateien analysieren und eine statistische Auswertung dieser Texteinheiten liefern sowie eine Liste aller im Dokument vorkommenden Wörter (Lexeme) mit ihren Frequenzangaben generieren, Konkordanz genannt. Die kann im weiteren Schritt zur Erstellung eines Wörterbuchs verwendet werden.
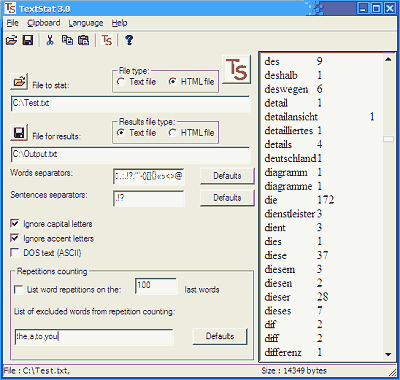
Schritte zur Erstellung der Konkordanz:
1. File to stat – Hier wird das zu analysierende Ausgangsdokument ausgewählt.
2. File for results – Das Analyseergebnis wird in einer Datei gespeichert, die hier definiert wird.
3. TS – Die Icon startet den Analysevorgang. Im rechten Fenster erscheint das Ergebnis.
Einstellungsmöglichkeiten:
Word separators – Definition der Wortgrenzen
Sentences separators – Definition der Satzgrenzen
Ignore capital letters – In der Liste werden gleichlautende Wortformen mit kleinem und großem Anfangsbuchstaben als eine Einheit gezählt.
Ignore accent letters – In der Liste werden gleichlautende Wortformen mit und ohne Akzent als eine Einheit gezählt.
Die Wortliste aus der gespeicherten Ergebnisdatei im Textformat kann gut in einer Tabellenkalkulation wie Excel bearbeitet werden; die Lexeme und ihre Frequenzangaben sind voneinander durch einen Tabulator getrennt. Die gereinigte Liste mit ausgewählten Begriffen aus dem Dokument kann dann als das Grundgerüst eines neuen Wörterbuchs dienen.